昨天我們一起認識了 random walk 這個方法,Pinterest 在實務上是如何利用這個技術的呢?讓我們今天一起來看 他們提出的 PinSage 演算法吧!
在昨天的文章中,我們介紹如何使用 random walk 產生 graph 的 embedding。而在實務上,Pinterest 為了配合自身需求,將 random walks 改寫得更有效率,提出 PinSage 演算法。其能夠生成結合圖形架構(graph structure)和節點特徵(node feature)的 embedding。
如同昨天的介紹,在 graph 的世界中,學習整個 graph 的架構是很重要的。作法是得到某節點鄰居們之資訊,再得到鄰居們的鄰居們之資訊,將其疊加,最後獲得整個 graph 的內容。
而有效率地計算這些資訊,對 Pinterest 來說有多重要呢?他們的 graph 有多於三百萬個節點,並高達一千八百萬個邊界(edge),是一個非常巨大的 graph,因此需要一個非常有效率的演算法。讓我們開始認識 PinSage 吧!
步驟:
目的:找尋可以當作推薦內容的節點。
Pinterest 有 pin 和 board 這兩個概念。Pin 是每一個涵蓋內容的小卡片,而 board 則是 pin 的集合,使用者可以將他們認為相關的 pin 放在同一個 board 中。
Pinterest 使用包含兩個 disjoint sets 的二分圖(bipartite graph):I(包含 pins)和 C(包含 boards)。並且,他們假設每個 pin 都有和文字或圖片內容相對應的屬性。利用每個 pin 的屬性和整個 graph 的結構,希望能夠產生可以用來做推薦系統的 embedding。
為了方便閱讀,之後提到節點時,同時包含 pins 和 boards 的節點,不會特別區分。
使用 localized convolutional modules 以產生 node embeddings。
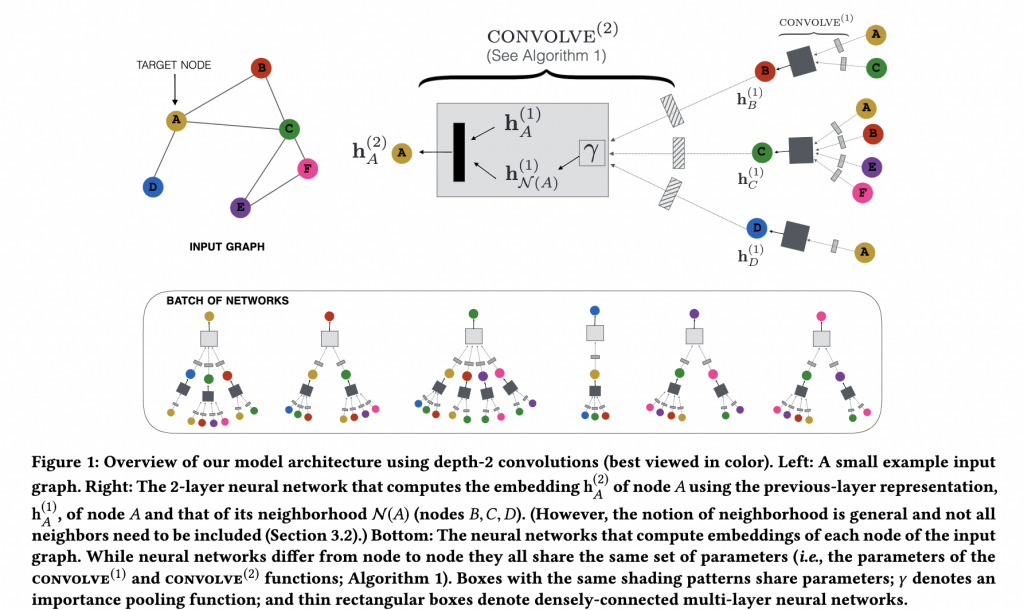
如 Figure 1 所示,先選定節點 A 做為計算的起點,依循步驟獲得自己本身的 embedding 和鄰居 BCD 的 embedding,最後計算出 A 的 embedding。

PinSage 的核心概念是 localized convolution,意即只 aggregate 每個節點 u 鄰居的資訊。
Algorithm 1 的步驟:
- 是將節點 u 的鄰居們 v 的 embedding Zᵥ,經過一個類神經網絡後,再使用 aggregator function r(此處使用加權總和),最後得到一組向量 nᵤ。
- 將 nᵤ 和 zᵤ 連接,再經過另一層神經網絡轉換。
- 最後,normalization 讓整個訓練過程更穩定且更有效率。
經過 Algorithm 1 計算後產生的 zᵤ 同時帶有自己和鄰居的資訊內容。
在前一個步驟中,鄰居的定義是什麼呢?一般常用的定義是採用距離 k 的鄰居。而 Pinterest 的革新之處在於他們提出 importance-based neighborhoods,鄰居的定義為對節點 u 最有影響力的 T 個節點。
什麼是具有影響力呢?具體而言,Pinterest 使用 random walks,從節點 u 出發,取路途中經過每個節點的次數(visit count),並計算 L1-normalized。而所謂的鄰居就是指從 u 出發,前 T 個高分之 normalized visit count 的節點。
這個方法的優點有二:
他們稱此方法為 importance pooling。
每次使用 Algorithm 1 後,都會得到節點 u 的新 embedding,Pinterest 會將很多 convolutions 相互疊在一起,以得到更多關於節點 u 的 local graph 結構資訊。
具體來說,一開始(layer 0) 的 representation 是 input node features,而第 k 層的 input 是第 k - 1 層的 representation output。
Pinterest 在此使用 max-margin-based loss function。基本概念是想要最大化 query item 和 positive examples 的內積,並希望 query item 和 negative examples 的內積要小於某個事先定義的 margin。
Positive examples 意指和 query 目標有關聯的物件。
Negative examples 意指和 query 目標沒有關聯的物件。
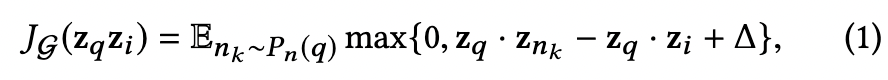
P_n(q) 是 q 的 negative examples 的 distribution。
經過這個 loss function 計算後,最後 Pinterest 能夠學到和目標節點相似的物件,並產生目標節點的 embedding。
那麼,有了 embedding 之後,要如何生成推薦內容呢?我們明天再來一起了解吧!
謝謝讀到最後的你,如果喜歡這系列,別忘了按下喜歡和訂閱,才不會錯過最新更新。
也歡迎到我的 medium 逛逛!
Reference:


 iThome鐵人賽
iThome鐵人賽